Avoiding inefficient uses of JPA.
Cost impacts of lazy and eager fetch joins
Get just the root parent of an object graph
Figure 81.1. DB Index(es)
alter table jpatune_moviegenre add constraint moviegenre_unique UNIQUE (movie_id, genre) create index movie_role_movie_fdx on jpatune_movierole(movie_id)
Figure 81.2. Service Tier Code
for (String id: movieIds) {
Movie m = dao.getMovieById(id);
m.getTitle();
}
Get just the root parent of an object graph with fetch=LAZY relationships
Figure 81.4. Relationships
public class Movie {
...
@ElementCollection(fetch=FetchType.LAZY)
@CollectionTable(
name="JPATUNE_MOVIEGENRE",
joinColumns=@JoinColumn(name="MOVIE_ID"),
uniqueConstraints=@UniqueConstraint(columnNames={"MOVIE_ID", "GENRE"}))
@Column(name="GENRE", length=20)
private Set<String> genres;
@ManyToOne(fetch=FetchType.LAZY,
cascade={CascadeType.PERSIST, CascadeType.DETACH})
@JoinColumn(name="DIRECTOR_ID")
private Director director;
@OneToMany(fetch=FetchType.LAZY,mappedBy="movie",
cascade={CascadeType.PERSIST, CascadeType.DETACH, CascadeType.REMOVE})
private Set<MovieRole> cast;
Two one-to-many relationships (cast and genres) -- genres is a non-entity ElementCollection
One one-to-one relationship (director)
All use fetch=LAZY
Figure 81.5. Generated SQL
select
movie0_.ID as ID1_2_0_,
movie0_.DIRECTOR_ID as DIRECTOR6_2_0_,
movie0_.MINUTES as MINUTES2_2_0_,
movie0_.RATING as RATING3_2_0_,
movie0_.RELEASE_DATE as RELEASE4_2_0_,
movie0_.TITLE as TITLE5_2_0_
from
JPATUNE_MOVIE movie0_
where
movie0_.ID=?Only parent table is queried
Children are lazily loaded

Unique scan of Movie primary key index to satisfy where clause and locate rowId
Row access by rowId to satisfy select clause
Figure 81.7. Relative Test Result
- 20 movies Fetch Lazy Thin Parent.Get Parent:warmups=2, rounds=10, ave=0.32 [+- 0.03] Fetch Lazy Thick Parent.Get Parent:warmups=2, rounds=10, ave=0.58 [+- 0.03]
* "Thick" parent has an extra Movie.plot text property mapped to potentially make child joins more expensive. Thin parent does not have Movie plot mapped so the results can focus on access to smaller, related entities.
Fetch=LAZY Speeds Access to Single Entity Core Information
Choosing fetch=LAZY for relationships allows efficient access to the core information for that entity without paying a price for loading unnecessary relations.
Get just the root parent of an object graph with fetch=EAGER relationships
Figure 81.8. Relationships
<entity class="ejava.jpa.examples.tuning.bo.Movie">
<attributes>
<many-to-one name="director" fetch="EAGER">
<join-column name="DIRECTOR_ID"/>
</many-to-one>
<one-to-many name="cast" fetch="EAGER" mapped-by="movie"/>
<element-collection name="genres" fetch="EAGER">
<column name="GENRE"/>
<collection-table name="JPATUNE_MOVIEGENRE">
<join-column name="MOVIE_ID"/>
<unique-constraint>
<column-name>MOVIE_ID</column-name>
<column-name>GENRE</column-name>
</unique-constraint>
</collection-table>
</element-collection>
<transient name="plot"/>
</attributes>
</entity>
public class MovieRole {
...
@ManyToOne(optional=false, fetch=FetchType.LAZY,
cascade={CascadeType.DETACH})
@JoinColumn(name="ACTOR_ID")
private Actor actor;
<entity class="ejava.jpa.examples.tuning.bo.MovieRole">
<attributes>
<many-to-one name="actor" fetch="EAGER">
<join-column name="ACTOR_ID"/>
</many-to-one>
</attributes>
</entity>
public class Actor {
...
@OneToOne(optional=false, fetch=FetchType.EAGER,
cascade={CascadeType.PERSIST, CascadeType.DETACH})
@MapsId
@JoinColumn(name="PERSON_ID")
private Person person;
public class Director {
...
@OneToOne(optional=false, fetch=FetchType.EAGER,
cascade={CascadeType.PERSIST, CascadeType.DETACH})
@JoinColumn(name="PERSON_ID")
@MapsId
private Person person;
Movie.director, Movie.genres, Movie.cast relationships overridden in XML to be fetch=EAGER
MovieRole.actor relationship overridden in XML to be fetch=EAGER
Director.person and Actor.person already fetch=EAGER
Figure 81.9. Generated SQL
select
movie0_.ID as ID1_2_5_,
movie0_.DIRECTOR_ID as DIRECTOR6_2_5_,
movie0_.MINUTES as MINUTES2_2_5_,
movie0_.RATING as RATING3_2_5_,
movie0_.RELEASE_DATE as RELEASE4_2_5_,
movie0_.TITLE as TITLE5_2_5_,
cast1_.MOVIE_ID as MOVIE4_2_7_,
cast1_.ID as ID1_4_7_,
cast1_.ID as ID1_4_0_,
cast1_.ACTOR_ID as ACTOR3_4_0_,
cast1_.MOVIE_ID as MOVIE4_4_0_,
cast1_.MOVIE_ROLE as MOVIE2_4_0_,
actor2_.PERSON_ID as PERSON1_0_1_,
person3_.ID as ID1_5_2_,
person3_.BIRTH_DATE as BIRTH2_5_2_,
person3_.FIRST_NAME as FIRST3_5_2_,
person3_.LAST_NAME as LAST4_5_2_,
person3_.MOD_NAME as MOD5_5_2_,
director4_.PERSON_ID as PERSON1_1_3_,
person5_.ID as ID1_5_4_,
person5_.BIRTH_DATE as BIRTH2_5_4_,
person5_.FIRST_NAME as FIRST3_5_4_,
person5_.LAST_NAME as LAST4_5_4_,
person5_.MOD_NAME as MOD5_5_4_,
genres6_.MOVIE_ID as MOVIE1_2_8_,
genres6_.GENRE as GENRE2_3_8_
from
JPATUNE_MOVIE movie0_
left outer join
JPATUNE_MOVIEROLE cast1_
on movie0_.ID=cast1_.MOVIE_ID
left outer join
JPATUNE_ACTOR actor2_
on cast1_.ACTOR_ID=actor2_.PERSON_ID
left outer join
JPATUNE_PERSON person3_
on actor2_.PERSON_ID=person3_.ID
left outer join
JPATUNE_DIRECTOR director4_
on movie0_.DIRECTOR_ID=director4_.PERSON_ID
left outer join
JPATUNE_PERSON person5_
on director4_.PERSON_ID=person5_.ID
left outer join
JPATUNE_MOVIEGENRE genres6_
on movie0_.ID=genres6_.MOVIE_ID
where
movie0_.ID=?Single query (as before), but this time it also brings in the entire object graph
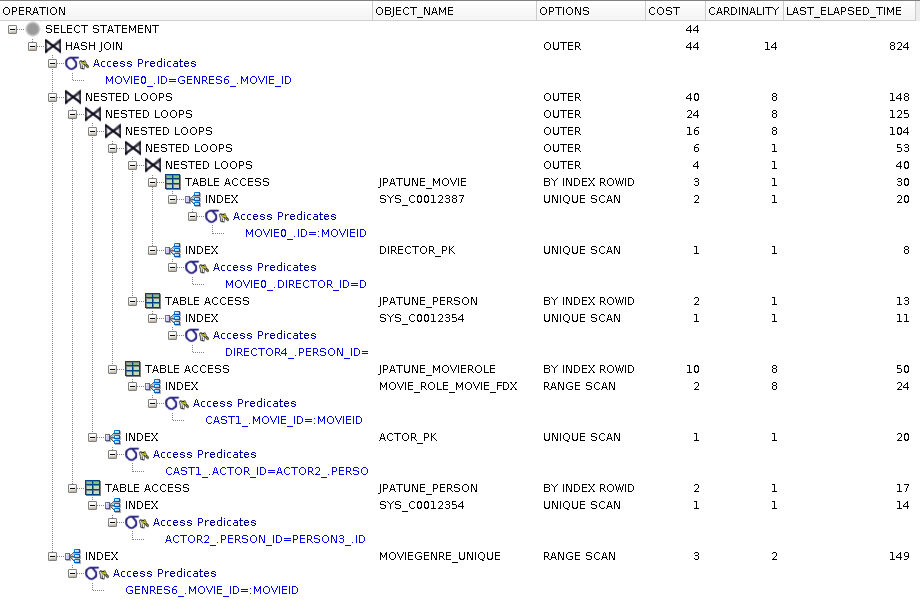
Explain plan shows use of indexes and no full table scans (a missing FK index for MovieRole.movie could have been costly)
Execution plan is significantly more costly than lazy alternative
Figure 81.11. Relative Test Result
- 20 movies Fetch Eager Thin Parent.Get Parent:warmups=2, rounds=10, ave=2.43 [+- 0.47] Fetch Eager Thick Parent.Get Parent:warmups=2, rounds=10, ave=2.59 [+- 0.06]
Fetch=EAGER for Single Entity adds Noticeable Overhead
Choosing fetch=EAGER for relationships will make access to a single entity within the relationship more expensive to access. Consider creating a value query, value query with a result class, or a native query when querying for only single entity under these conditions.
Get just the root parent and *ONLY* the parent of an object graph with fetch=EAGER relationships by using a NativeQuery and Result Class
Figure 81.13. DAO Code
public Movie getMovieByIdUnfetched(String id) {
List<Movie> movies=createQuery(
String.format("select new %s(m.id, m.minutes, m.rating, m.releaseDate, m.title) ", Movie.class.getName()) +
"from Movie m " +
"where id=:id", Movie.class)
.setParameter("id", id)
.getResultList();
return movies.isEmpty() ? null : movies.get(0);
}
public Movie(String id, Integer minutes, String rating, Date releaseDate, String title) {
this.id=id;
this.minutes = minutes;
this.rating=rating;
this.mrating=MovieRating.getFromMpaa(rating);
this.releaseDate = releaseDate;
this.title=title;
}
We define an alternate JPA-QL query for provider to use that does not include relationships
Result class not mapped beyond this query -- does not have to be an entity class
Figure 81.14. Generated JPAQL and SQL
"select new ejava.jpa.examples.tuning.bo.Movie(m.id, m.minutes, m.rating, m.releaseDate, m.title)
from Movie m where id=:id",
params={id=m270003}
select
movie0_.ID as col_0_0_,
movie0_.MINUTES as col_1_0_,
movie0_.RATING as col_2_0_,
movie0_.RELEASE_DATE as col_3_0_,
movie0_.TITLE as col_4_0_
from
JPATUNE_MOVIE movie0_
where
movie0_.ID=?Value query with result class constructor permits a bypass of fetch=EAGER relationships

Execution plan identical to fetch=LAZY case
Figure 81.16. Relative Test Result
Fetch Eager Thin Parent.Get Just Parent:warmups=2, rounds=10, ave=0.32 [+- 0.02] Fetch Eager Thick Parent.Get Just Parent:warmups=2, rounds=10, ave=0.32 [+- 0.02] Fetch Lazy Thin Parent.Get Just Parent:warmups=2, rounds=10, ave=0.34 [+- 0.03] Fetch Lazy Thick Parent.Get Just Parent:warmups=2, rounds=10, ave=0.32 [+- 0.02]
* Thick/Thin or Eager/Lazy should not matter to this approach since we only access a specific set of fields in the Movie that does not include Movie.plot.
Use JPA Value or Native Queries to Override Relationship Definitions
JPA provides many escape hatches to achieve desired results. Use JPAQL value queries with Object[], Tuple, or custom result class -or- use SQL to provide efficient override of fetch=EAGER definitions.
Result Class Instances are not Managed
Even though we used an entity class in this example, it is being used as a simple POJO and the returned instance is not managed. Result Classes for value queries provide convenient type-safe access to results. However, they are unmanaged and cannot be used for follow-on entity operations.
Get parent and children in an object graph
Figure 81.17. DB Index(es)
alter table jpatune_moviegenre add constraint moviegenre_unique UNIQUE (movie_id, genre) create index movie_role_movie_fdx on jpatune_movierole(movie_id)
Figure 81.18. Service Tier Code
for (String id: movieIds) {
Movie m = dao.getMovieById(id);
if (m.getDirector()!=null) { m.getDirector().getPerson().getLastName(); }
m.getGenres().iterator().next();
for (MovieRole role: m.getCast()) {
if (role.getActor()!=null) { role.getActor().getPerson().getLastName(); }
}
}
Get parent and children in an object graph with fetch=LAZY relationships
Query for parent
select movie0_.ID as ID1_2_0_, movie0_.DIRECTOR_ID as DIRECTOR6_2_0_, movie0_.MINUTES as MINUTES2_2_0_, movie0_.RATING as RATING3_2_0_, movie0_.RELEASE_DATE as RELEASE4_2_0_, movie0_.TITLE as TITLE5_2_0_ from JPATUNE_MOVIE movie0_ where movie0_.ID=?Query for Movie.director role
select director0_.PERSON_ID as PERSON1_1_0_ from JPATUNE_DIRECTOR director0_ where director0_.PERSON_ID=?;Query for Movie.director.person identity
select person0_.ID as ID1_5_0_, person0_.BIRTH_DATE as BIRTH2_5_0_, person0_.FIRST_NAME as FIRST3_5_0_, person0_.LAST_NAME as LAST4_5_0_, person0_.MOD_NAME as MOD5_5_0_ from JPATUNE_PERSON person0_ where person0_.ID=?;Query for Movie.genre values
select genres0_.MOVIE_ID as MOVIE1_2_0_, genres0_.GENRE as GENRE2_3_0_ from JPATUNE_MOVIEGENRE genres0_ where genres0_.MOVIE_ID=?;Query for Movie.cast entities
select cast0_.MOVIE_ID as MOVIE4_2_1_, cast0_.ID as ID1_4_1_, cast0_.ID as ID1_4_0_, cast0_.ACTOR_ID as ACTOR3_4_0_, cast0_.MOVIE_ID as MOVIE4_4_0_, cast0_.MOVIE_ROLE as MOVIE2_4_0_ from JPATUNE_MOVIEROLE cast0_ where cast0_.MOVIE_ID=?;Query for MovieRole.actor entity
select actor0_.PERSON_ID as PERSON1_0_0_ from JPATUNE_ACTOR actor0_ where actor0_.PERSON_ID=? ... --repeated for each member of the Movie.castQuery for Actor.person entity
select person0_.ID as ID1_5_0_, person0_.BIRTH_DATE as BIRTH2_5_0_, person0_.FIRST_NAME as FIRST3_5_0_, person0_.LAST_NAME as LAST4_5_0_, person0_.MOD_NAME as MOD5_5_0_ from JPATUNE_PERSON person0_ where person0_.ID=?; ... --repeated for each member of the Movie.cast






Fetch Lazy Thin Parent.Get Parent and Children:warmups=2, rounds=10, ave=7.25 [+- 0.91] Fetch Lazy Thick Parent.Get Parent and Children:warmups=2, rounds=10, ave=7.25 [+- 0.92]
Make Sparse use of Object Graphs when using fetch=LAZY
Fetch=LAZY is intended for access to a minimal set of objects within a graph. Although each individual query by primary key is quite inexpensive, the sum total (factoring in cardinality) is significant. Consider adding a JOIN FETCH query to your DAO when accessing entire object graph declared with fetch=LAZY.
Get parent and children in an object graph with fetch=EAGER relationships
Loading of the object graph occurs in single DB call
Same cost loading object graph -- whether accessing single or all entities
Figure 81.29. Relative Test Result
Fetch Eager Thin Parent.Get Parent and Children:warmups=2, rounds=10, ave=2.26 [+- 0.06] Fetch Eager Thick Parent.Get Parent and Children:warmups=2, rounds=10, ave=2.57 [+- 0.06]
Fetch=EAGER Efficient when Accessing Relations
Use fetch=EAGER if related entity *always*/*mostly* accessed. Suggest using a JOIN FETCH query when fetch=LAZY is defined and need entire object graph.
Get parent and children in an object graph with JOIN FETCH query
Figure 81.31. DAO Code/JPAQL
public Movie getMovieFetchedByIdFetched(String id) {
List<Movie> movies = createQuery(
"select m from Movie m " +
"left join fetch m.genres " +
"left join fetch m.director d " +
"left join fetch d.person " +
"left join fetch m.cast role " +
"left join fetch role.actor a " +
"left join fetch a.person " +
"where m.id=:id", Movie.class)
.setParameter("id", id)
.getResultList();
return movies.isEmpty() ? null : movies.get(0);
}
EAGER aspects adding by query adding FETCH to JOIN query construct
Figure 81.32. Generated SQL
select
movie0_.ID as ID1_2_0_,
director2_.PERSON_ID as PERSON1_1_1_,
person3_.ID as ID1_5_2_,
cast4_.ID as ID1_4_3_,
actor5_.PERSON_ID as PERSON1_0_4_,
person6_.ID as ID1_5_5_,
movie0_.DIRECTOR_ID as DIRECTOR6_2_0_,
movie0_.MINUTES as MINUTES2_2_0_,
movie0_.RATING as RATING3_2_0_,
movie0_.RELEASE_DATE as RELEASE4_2_0_,
movie0_.TITLE as TITLE5_2_0_,
genres1_.MOVIE_ID as MOVIE1_2_0__,
genres1_.GENRE as GENRE2_3_0__,
person3_.BIRTH_DATE as BIRTH2_5_2_,
person3_.FIRST_NAME as FIRST3_5_2_,
person3_.LAST_NAME as LAST4_5_2_,
person3_.MOD_NAME as MOD5_5_2_,
cast4_.ACTOR_ID as ACTOR3_4_3_,
cast4_.MOVIE_ID as MOVIE4_4_3_,
cast4_.MOVIE_ROLE as MOVIE2_4_3_,
cast4_.MOVIE_ID as MOVIE4_2_1__,
cast4_.ID as ID1_4_1__,
person6_.BIRTH_DATE as BIRTH2_5_5_,
person6_.FIRST_NAME as FIRST3_5_5_,
person6_.LAST_NAME as LAST4_5_5_,
person6_.MOD_NAME as MOD5_5_5_
from
JPATUNE_MOVIE movie0_
left outer join
JPATUNE_MOVIEGENRE genres1_
on movie0_.ID=genres1_.MOVIE_ID
left outer join
JPATUNE_DIRECTOR director2_
on movie0_.DIRECTOR_ID=director2_.PERSON_ID
left outer join
JPATUNE_PERSON person3_
on director2_.PERSON_ID=person3_.ID
left outer join
JPATUNE_MOVIEROLE cast4_
on movie0_.ID=cast4_.MOVIE_ID
left outer join
JPATUNE_ACTOR actor5_
on cast4_.ACTOR_ID=actor5_.PERSON_ID
left outer join
JPATUNE_PERSON person6_
on actor5_.PERSON_ID=person6_.ID
where
movie0_.ID=?;Query identical to fetch=EAGER case
Figure 81.34. Relative Test Result
Fetch Lazy Thin Parent.Get Parent with Fetched Children:warmups=2, rounds=10, ave=2.56 [+- 0.80] Fetch Lazy Thick Parent.Get Parent with Fetched Children:warmups=2, rounds=10, ave=2.54 [+- 0.08] Fetch Eager Thin Parent.Get Parent with Fetched Children:warmups=2, rounds=10, ave=2.24 [+- 0.06] Fetch Eager Thick Parent.Get Parent with Fetched Children:warmups=2, rounds=10, ave=2.58 [+- 0.05]
Make use of JPA Queries to Achieve Tuned-for-Use Query
JPA provides several means to access an entity and its relationships. The properties defined for the relationship help define the default query semantics -- which may not be appropriate for all uses. Leverage JOIN FETCH queries when needing to fully load specific relationships prior to ending the transaction.
Pulling back entire rows from table rather than just the count
Figure 81.35. DB Index(es)
alter table jpatune_moviegenre add constraint moviegenre_unique UNIQUE (movie_id, genre) create index movie_role_movie_fdx on jpatune_movierole(movie_id)
Get size of a relationship collection.
Figure 81.37. DAO Code/JPAQL
public int getMovieCastCountByDAORelation(String movieId) {
Movie m = em.find(Movie.class, movieId);
return m==null ? 0 : m.getCast().size();
}
DAO first gets Movie by primary key
DAO follows up by accessing size of relationship
Figure 81.38. Generated SQL - Fetch=LAZY
select
movie0_.ID as ID1_2_0_,
movie0_.DIRECTOR_ID as DIRECTOR6_2_0_,
movie0_.MINUTES as MINUTES2_2_0_,
movie0_.RATING as RATING3_2_0_,
movie0_.RELEASE_DATE as RELEASE4_2_0_,
movie0_.TITLE as TITLE5_2_0_
from
JPATUNE_MOVIE movie0_
where
movie0_.ID=?select
cast0_.MOVIE_ID as MOVIE4_2_1_,
cast0_.ID as ID1_4_1_,
cast0_.ID as ID1_4_0_,
cast0_.ACTOR_ID as ACTOR3_4_0_,
cast0_.MOVIE_ID as MOVIE4_4_0_,
cast0_.MOVIE_ROLE as MOVIE2_4_0_
from
JPATUNE_MOVIEROLE cast0_
where
cast0_.MOVIE_ID=?Provider will issue follow-on query for all entities in relation
Entity data not used by DAO -- i.e. wasted
Provider will issue one query for entire object graph, to include entities in relation
Entity data not used by DAO -- i.e. even more data is wasted
Figure 81.40. Relative Test Result
Size Lazy.DAO Relation Count:warmups=2, rounds=10, ave=1.83 [+- 0.82] Size Eager.DAO Relation Count:warmups=2, rounds=10, ave=5.40 [+- 0.83]
Using Relation Collections to Just Obtain Size is Inefficient
Pulling back relationship graphs to just obtain the count in that relationship is inefficient and requires DB to do much more work than it has to.
Query for relationships and count resulting rows
Figure 81.41. DAO Code/JPAQL
public int getMovieCastCountByDAO(String movieId) {
return createQuery(
"select role " +
"from Movie m " +
"join m.cast role " +
"where m.id=:id", MovieRole.class)
.setParameter("id", movieId)
.getResultList().size();
}
"select role from Movie m join m.cast role where m.id=:id", params={id=m48306}DAO forms query for just related entities
Figure 81.42. Generated SQL - Fetch=LAZY
select
cast1_.ID as ID1_4_,
cast1_.ACTOR_ID as ACTOR3_4_,
cast1_.MOVIE_ID as MOVIE4_4_,
cast1_.MOVIE_ROLE as MOVIE2_4_
from
JPATUNE_MOVIE movie0_
inner join
JPATUNE_MOVIEROLE cast1_
on movie0_.ID=cast1_.MOVIE_ID
where
movie0_.ID=?Provider forms query for related entities
Figure 81.43. Generated SQL - Fetch=EAGER
select
cast1_.ID as ID1_4_,
cast1_.ACTOR_ID as ACTOR3_4_,
cast1_.MOVIE_ID as MOVIE4_4_,
cast1_.MOVIE_ROLE as MOVIE2_4_
from
JPATUNE_MOVIE movie0_
inner join
JPATUNE_MOVIEROLE cast1_
on movie0_.ID=cast1_.MOVIE_ID
where
movie0_.ID=?--this is repeated for each MovieRole.actor
select
actor0_.PERSON_ID as PERSON1_0_0_
from
JPATUNE_ACTOR actor0_
where
actor0_.PERSON_ID=?
select
person0_.ID as ID1_5_0_,
person0_.BIRTH_DATE as BIRTH2_5_0_,
person0_.FIRST_NAME as FIRST3_5_0_,
person0_.LAST_NAME as LAST4_5_0_,
person0_.MOD_NAME as MOD5_5_0_
from
JPATUNE_PERSON person0_
where
person0_.ID=?Provider forms query for related entities and fetch=EAGER relationship specification causes additional MovieRole.actor to be immediately obtained -- except through separate queries by primary key.
Figure 81.44. Relative Test Result
Size Lazy.DAO Count:warmups=2, rounds=10, ave=1.37 [+- 0.03] Size Eager.DAO Count:warmups=2, rounds=10, ave=16.82 [+- 1.33]
Using fetch=EAGER Relationships can Magnify Data Retrieval Issues
When the entity model over-uses fetch=EAGER, the negative results can be magnified when pulling back unnecessary information from the database.
Issue query to DB to return relationship count
Figure 81.45. DAO Code/JPAQL
public int getMovieCastCountByDB(String movieId) {
return createQuery(
"select count(role) " +
"from Movie m " +
"join m.cast role " +
"where m.id=:id", Number.class)
.setParameter("id", movieId)
.getSingleResult().intValue();
}
"select count(role) from Movie m join m.cast role where m.id=:id", params={id=m48306}Requesting count(role) rather than returning all roles and counting in DAO.
Figure 81.46. Generated SQL
select
count(cast1_.ID) as col_0_0_
from
JPATUNE_MOVIE movie0_
inner join
JPATUNE_MOVIEROLE cast1_
on movie0_.ID=cast1_.MOVIE_ID
where
movie0_.ID=?Produces a single result/row

DB has already optimized the query to remove unnecessary JOIN
Figure 81.48. Relative Test Result
Size Lazy.DB Count:warmups=2, rounds=10, ave=0.50 [+- 0.04] Size Eager.DB Count:warmups=2, rounds=10, ave=0.45 [+- 0.02]
* fetch=LAZY or EAGER has no impact in this solution
Perform Counts within DB
It is much more efficient to perform counts within database than to count rows from data returned.
Restructure query to DB to count relations without JOIN
Figure 81.49. DAO Code/JPAQL
public int getCastCountForMovie(String movieId) {
return createQuery(
"select count(*) " +
"from MovieRole role " +
"where role.movie.id=:id", Number.class)
.setParameter("id", movieId)
.getSingleResult().intValue();
}
"select count(*) from MovieRole role where role.movie.id=:id", params={id=m48306}Querying from MovieRole side allows removal of unnecessary JOIN
Figure 81.50. Generated SQL
select
count(*) as col_0_0_
from
JPATUNE_MOVIEROLE movierole0_
where
movierole0_.MOVIE_ID=?SQL generated queries single table
No improvement in execution plan since DB already performed this optimization in our last attempt
Figure 81.52. Relative Test Result
Size Lazy.DB Count no Join:warmups=2, rounds=10, ave=0.47 [+- 0.01] Size Eager.DB Count no Join:warmups=2, rounds=10, ave=0.44 [+- 0.02]
* fetch=LAZY or EAGER has no impact in this solution
Look to Remove Unnecessary JOINs
Although in this and the previous case the DB looks to have already optimized the query, try to eliminate unnecessary complexity within the query.
Performing separate subqueries off initial query
Get people who have acted in same movie as a specific actor
Figure 81.53. DB Index(es)
create index movierole_actor_movie_cdx on jpatune_movierole(actor_id, movie_id) create index movierole_movie_actor_cdx on jpatune_movierole(movie_id, actor_id)
Using DAO to perform initial query and follow-on queries based on results
Figure 81.55. DAO Code/JPAQL
public Collection<Person> oneStepFromPersonByDAO(Person p) {
Collection<Person> result = new HashSet<Person>();
//performing core query
List<String> movieIds = createQuery(
"select role.movie.id from MovieRole role " +
"where role.actor.person.id=:personId", String.class)
.setParameter("personId", p.getId())
.getResultList();
//loop through results and issue sub-queries
for (String mid: movieIds) {
List<Person> people = createQuery(
"select role.actor.person from MovieRole role " +
"where role.movie.id=:movieId", Person.class)
.setParameter("movieId", mid)
.getResultList();
result.addAll(people);
}
return result;
}
"select role.movie.id from MovieRole role where role.actor.person.id=:personId", params={personId=p73897}//repeated for each returned movie above
"select role.actor.person from MovieRole role where role.movie.id=:movieId", params={movieId=m239584}DAO makes N separate queries based on results of first query
Distinct was not required in query since it was issued per-movie. Distinct was handed within the DAO using a Java Set to hold the results and hashcode()/equals() implemented within Person class.
Figure 81.56. Generated SQL
select
movierole0_.MOVIE_ID as col_0_0_
from
JPATUNE_MOVIEROLE movierole0_,
JPATUNE_ACTOR actor1_
where
movierole0_.ACTOR_ID=actor1_.PERSON_ID
and actor1_.PERSON_ID=?--repeated for each returned movie above
select
person2_.ID as ID1_5_,
person2_.BIRTH_DATE as BIRTH2_5_,
person2_.FIRST_NAME as FIRST3_5_,
person2_.LAST_NAME as LAST4_5_,
person2_.MOD_NAME as MOD5_5_
from
JPATUNE_MOVIEROLE movierole0_,
JPATUNE_ACTOR actor1_
inner join
JPATUNE_PERSON person2_
on actor1_.PERSON_ID=person2_.ID
where
movierole0_.ACTOR_ID=actor1_.PERSON_ID
and movierole0_.MOVIE_ID=?
SQL generated queries single table

Range scan of compound index(actor_id, person_id) used to satisfy the person_id in where clause and movie_id for select clause
* Query was optimized to bypass Actor table
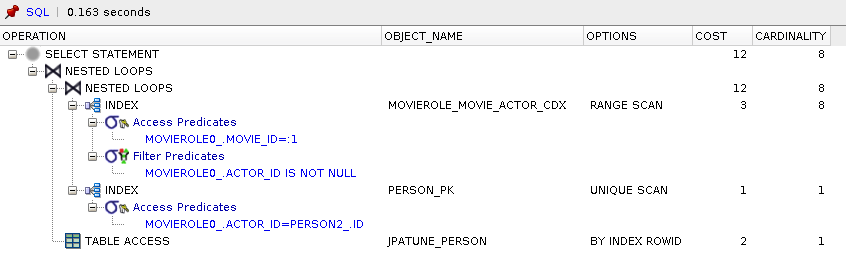
Range scan on compound_index(movie_id, actor_id) to satisfy where condition for Movie.id and locate MovieRole rowId
Unique scan of Person primary key index to obtain rowId for Person.id=MovieRole.actor.id
Person row accessed by rowId to satisfy select clause
* Query was optimized to bypass Actor table
** Compound index(movie_id, actor_id) permitted MovieRole table and lookup of MovieRole.actorId to be bypassed.
Figure 81.59. Relative Test Result
-3924 people found Loop Lazy.DAO Loop:warmups=2, rounds=10, ave=4.91 [+- 0.88]
Beware of Query Loops Driven from Query Results
Query loops driven off of previous query results can be a sign the follow-queries could have been combined with the initial query to be accomplished within the database within a single statement.
Also beware of how the loop size can grow over the lifetime of the application. The number may grow significantly after testing/initial deployment to a significant size (i.e., from 100 to 100K loops). Defining as a single statement and applying paging limits can help speed the originally flawed implementation.
Expressing nest query as subquery to resolve within database.
Figure 81.60. DAO Code/JPAQL
public List<Person> oneStepFromPersonByDB(Person p) {
return createQuery(
"select distinct role.actor.person from MovieRole role " +
"where role.movie.id in (" +
"select m.id from Movie m " +
"join m.cast role2 " +
"where role2.actor.person.id=:id)", Person.class)
.setParameter("id", p.getId())
.getResultList();
}
"select distinct role.actor.person from MovieRole role
where role.movie.id in (
select m.id from Movie m join m.cast role2
where role2.actor.person.id=:id
)",
params={id=p73897}
Distinct was required to remove duplicates
Figure 81.61. Generated SQL
select
distinct person2_.ID as ID1_5_,
person2_.BIRTH_DATE as BIRTH2_5_,
person2_.FIRST_NAME as FIRST3_5_,
person2_.LAST_NAME as LAST4_5_,
person2_.MOD_NAME as MOD5_5_
from
JPATUNE_MOVIEROLE movierole0_,
JPATUNE_ACTOR actor1_
inner join
JPATUNE_PERSON person2_
on actor1_.PERSON_ID=person2_.ID
where
movierole0_.ACTOR_ID=actor1_.PERSON_ID
and (
movierole0_.MOVIE_ID in (
select
movie3_.ID
from
JPATUNE_MOVIE movie3_
inner join
JPATUNE_MOVIEROLE cast4_
on movie3_.ID=cast4_.MOVIE_ID,
JPATUNE_ACTOR actor5_
where
cast4_.ACTOR_ID=actor5_.PERSON_ID
and actor5_.PERSON_ID=?
)
)SQL generated uses a non-correlated subquery
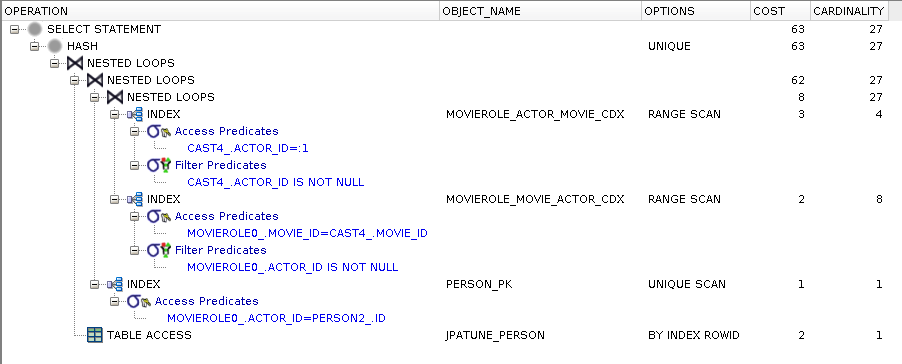
Range scan of MovieRole composite(actor_id, movie_id) used to satisfy subquery where clause for person_id and obtain movie_id
Range scan of MovieRole composite(movie_id, actor_id) used to join movie_ids with root query and obtain person_id
Unique scan of Person primary key index to locate rowId
Person row accessed by rowId
* cast4_ and movierole0_ are both MovieRoles. cast4_ is joined with Movie and subject Person in subquery. movierole0_ is joined with Movie and associated Person in root query.
** execution plan indicates subquery could have been re-written as a JOIN
Figure 81.63. Relative Test Result
-3924 people found Loop Lazy.DB Loop Distinct:warmups=2, rounds=10, ave=2.52 [+- 0.09]
Delegate Query Logic to Database
If possible, express query as a single transaction to the database rather than pulling data back and re-issuing subqueries from the DAO. Apply paging constraints in order to address issues with excess growth over time.
Placing reasonable limits on amount of data returned
Figure 81.64. DB Index(es)
alter table jpatune_moviegenre add constraint moviegenre_unique UNIQUE (movie_id, genre) create index movie_role_movie_fdx on jpatune_movierole(movie_id)
Figure 81.65. Service Tier Code
dao.oneStepFromPerson(kevinBacon, offset, PAGE_SIZE, "role.actor.person.lastName ASC")
* Service tier provides not only offset and limit information, but would also benefit from using a sort. The DAO would have to pull back all rows in order to implement the sort within the DAO -- while the DB-based solution can leave all data within the database. Sort will only be implemented here in the DB-based solution.
Implementing paging within the DAO
Figure 81.66. DAO Code/JPAQL
public Collection<Person> oneStepFromPersonByDAO(Person p, Integer offset, Integer limit, String orderBy) {
Collection<Person> result = new HashSet<Person>();
//performing core query
List<String> movieIds = createQuery(
"select role.movie.id from MovieRole role " +
"where role.actor.person.id=:personId", String.class)
.setParameter("personId", p.getId())
.getResultList();
//loop through results and issue sub-queries
int pos=0;
for (String mid: movieIds) {
List<Person> people = createQuery(
"select role.actor.person from MovieRole role " +
"where role.movie.id=:movieId", Person.class)
.setParameter("movieId", mid)
.getResultList();
if (offset==null || (offset!=null && pos+people.size() > offset)) {
for(Person pp: people) {
if (offset==null || pos>=offset) {
result.add(pp);
if (limit!=null && result.size() >= limit) { break; }
}
pos+=1;
}
} else {
pos+=people.size();
}
if (limit!=null && result.size() >= limit) { break; }
}
return result;
}
DAO logic gets complicated when self-implementing paging.
OrderBy is not implemented by this DAO algorithm. All rows in the table would be required in order to perform ordering within the DAO.
Figure 81.69. Relative Test Result
Loop Lazy.DAO Page 0:warmups=1, rounds=10, ave=0.39 [+- 0.09] Loop Lazy.DAO Page 10:warmups=1, rounds=10, ave=1.01 [+- 0.45] Loop Lazy.DAO Page 50:warmups=1, rounds=10, ave=2.80 [+- 0.79] Loop Eager.DAO Page 0:warmups=1, rounds=10, ave=0.38 [+- 0.10] Loop Eager.DAO Page 10:warmups=1, rounds=10, ave=1.10 [+- 0.64] Loop Eager.DAO Page 50:warmups=1, rounds=10, ave=2.53 [+- 0.06]
This example performs better or equal to previous loop/subquery example when earlier pages are requested -- thus fewer rows returned
fetch=EAGER/LAZY have no impact on this test since the entity queried for has no relationships
Performance Degrades in DAO as Row Sizes Increase
Paging within the Java code starts off near equivalent to the database solution for small row sizes but gradually gets worse when row sizes increase and later pages are requested.
Implementing paging within the database
Figure 81.70. DAO Code/JPAQL
public List<Person> oneStepFromPersonByDB(Person p, Integer offset, Integer limit, String orderBy) {
return withPaging(createQuery(
"select distinct role.actor.person from MovieRole role " +
"where role.movie.id in (" +
"select m.id from Movie m " +
"join m.cast role2 " +
"where role2.actor.person.id=:id)", Person.class), offset, limit, orderBy)
.setParameter("id", p.getId())
.getResultList();
}
"select distinct role.actor.person from MovieRole role
where role.movie.id in (
select m.id from Movie m join m.cast role2
where role2.actor.person.id=:id
) order by role.actor.person.lastName ASC",
params={id=p73897}, offset=500, limit=50
JPA calls to TypedQuery.setFirstResult(), setMaxResults(), and adding the orderBy to the text of the query are abstracted behind withQuery() and createQuery() helper functions within the DAO example class and are not shown here
Figure 81.71. Generated SQL
select
*
from
( select
row_.*,
rownum rownum_
from
( select
distinct person2_.ID as ID1_5_,
person2_.BIRTH_DATE as BIRTH2_5_,
person2_.FIRST_NAME as FIRST3_5_,
person2_.LAST_NAME as LAST4_5_,
person2_.MOD_NAME as MOD5_5_
from
JPATUNE_MOVIEROLE movierole0_,
JPATUNE_ACTOR actor1_
inner join
JPATUNE_PERSON person2_
on actor1_.PERSON_ID=person2_.ID,
JPATUNE_PERSON person7_
where
movierole0_.ACTOR_ID=actor1_.PERSON_ID
and actor1_.PERSON_ID=person7_.ID
and (
movierole0_.MOVIE_ID in (
select
movie3_.ID
from
JPATUNE_MOVIE movie3_
inner join
JPATUNE_MOVIEROLE cast4_
on movie3_.ID=cast4_.MOVIE_ID,
JPATUNE_ACTOR actor5_
where
cast4_.ACTOR_ID=actor5_.PERSON_ID
and actor5_.PERSON_ID=?
)
)
order by
person7_.LAST_NAME ASC ) row_
where
rownum <= ?)
where
rownum_ > ?Generated SQL is essentially the same as the looping/subquery example except with the addition of "order by" and paging constructs.
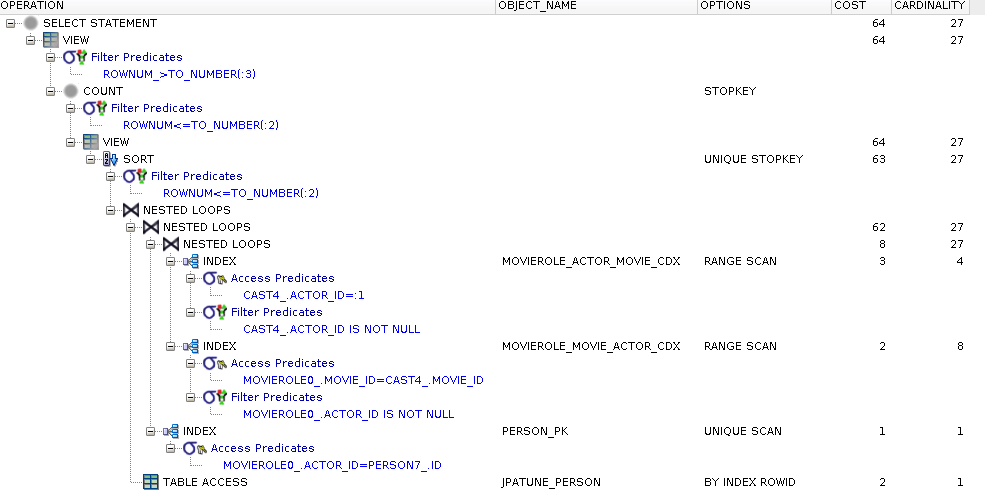
Execution plan is similar as described in the looping/subquery example
Extra cost to sort rows prior to paging operation added
Figure 81.73. Relative Test Result
Loop Lazy.DB Page 0:warmups=1, rounds=10, ave=0.32 [+- 0.02] Loop Lazy.DB Page 10:warmups=1, rounds=10, ave=0.31 [+- 0.01] Loop Lazy.DB Page 50:warmups=1, rounds=10, ave=0.32 [+- 0.01] Loop Eager.DB Page 0:warmups=1, rounds=10, ave=0.32 [+- 0.01] Loop Eager.DB Page 10:warmups=1, rounds=10, ave=0.32 [+- 0.01] Loop Eager.DB Page 50:warmups=1, rounds=10, ave=0.32 [+- 0.00]
DB-based Paging Scales
Since only the requested page of rows is returned, delegating paging to the database provides consistent performance for varying row quantities.
Doing Paging within DB enables Sorting
Implementing paging across multiple subquery calls to the database can get ugly and error-prone. Implementing paging for a single query issued to the database is quite trivial.
Hidden performance costs for fetch and resolving with JOIN FETCH and value queries
Hidden performance costs for row counts and resolving with a query function
Performance costs when issuing repeated queries of an initial query from DAO and resolving using subqueries in database
Performance and functional costs when implementing paging in DAO and resolving by delegating paging to database